The Google File System
Tags:#computer-science
#article
“The Google File System”, first paper from the list. Shortly, it’s a great paper on how the approach “Accept the inevitable occurrence of failure within the system” can be applied to the large scale File System with thousands of nodes and hundreds of concurrent users.
We have reexamined traditional choices and explored radically different points in the design space.
- Component failures are the norm rather than the exception.
- Files are huge by traditional standards.
- Most files are mutated by appending new data rather than overwriting existing data.
- Co-designing the applications and the file system API benefits the overall system by increasing our flexibility.
It was written by Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung and published in 2003. The details of how Google engineers have addressed these approaches are described in the paper. Design principles, system interactions, master server and its functionality, fault tolerance approaches, and measurements data, based on production and internal clusters usage metrics - all this can be found inside.
Key points from the paper:
- Design Goals:
- Scalability: Handle large data volumes and a large number of machines.
- Fault Tolerance: Ensure robustness against hardware failures.
- High Throughput: Optimize for high throughput rather than low latency.
- Simple Interface: Provide a straightforward API for developers.
- Architecture:
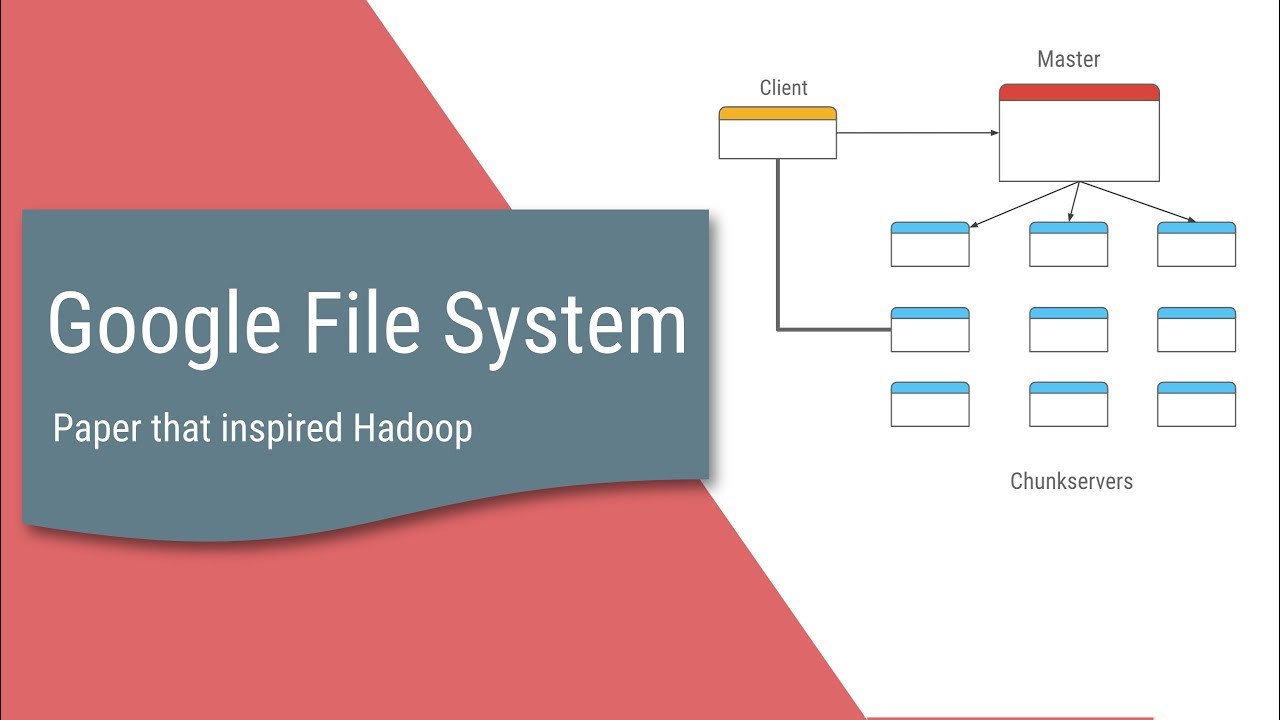
- Master-Slave Model: The architecture consists of a single master and multiple chunkservers.
- Master Node: Manages metadata, including the namespace, access control information, and file-to-chunk mappings.
- Chunkservers: Store the actual data in fixed-size chunks (64 MB). They manage replication and handle read/write requests.
- Data Storage:
- Chunks: Files are divided into chunks, each identified by a unique chunk handle.
- Replication: Chunks are replicated across multiple chunkservers to ensure fault tolerance. Default replication factor is 3.
- Fault Tolerance:
- Replication: Ensures data is not lost if a chunkserver fails.
- Heartbeat Mechanism: Chunkservers send periodic heartbeats to the master to report status.
- Re-replication: The master re-replicates chunks when it detects that replication is below the desired level.
- Consistency Model:
- Write-once: Files are typically written once and then read many times. Supports appending but not random writes.
- Consistency Guarantees: Changes are visible immediately after they are committed.
- Performance:
- Optimized for Large Files: Design focuses on handling large files and large-scale data operations.
- Write Optimization: Large sequential writes are optimized to be more efficient than random writes.
- Namespace Management:
- Hierarchical Namespace: Files are organized in a hierarchical directory structure.
- Metadata Caching: Metadata is cached in the master to reduce access latency.
- Client Interaction:
- File Operations: Clients interact with the master to obtain chunk locations, then directly communicate with chunkservers for read/write operations.
- Pipelining: Operations are pipelined to reduce latency and improve throughput.
- Design Decisions:
- Simple File Semantics: Simplicity of the file system’s semantics allows it to be implemented efficiently and scaled easily.
- Trade-offs: Some traditional file system features, like strong consistency for all operations, are sacrificed to meet scalability and fault tolerance goals.
The line of thought used to solve the tasks mentioned at the beginning is again emphasized in the Conclusion section.
We started by reexamining traditional file system assumptions in light of our current and anticipated application workloads and technological environment. Our observations have led to radically different points in the design space. We treat component failures as the norm rather than the exception, optimize for huge files that are mostly appended to (perhaps concurrently) and then read (usually sequentially), and both extend and relax the standard file system interface to improve the overall system.